
IA COGNITO – EP02 – Intelligence Artificielle et Ethique
L’intelligence artificielle est un domaine scientifique qui progresse à grand pas et les applications se multiplient. Toutefois, cet essor soulève un certain nombre de questions liées à l’éthique. L’Europe en a même fait son cheval de bataille. Mais qu’est ce que l’éthique ? Comment s’applique-t-elle et quels impacts peut-elle avoir sur le développement de l’IA ? Toutes ces questions, nous tenterons de les élucider au travers de ce podcast.
Définir l’éthique
Définitions de l’éthique et des termes associés
Avant de rentrer dans le vif du sujet, il est important de définir ensemble ce qu’est l’éthique et les différentes notions qui lui sont liées. De cette façon, nous pourrons établir des bases communes et éviter toute incompréhension.
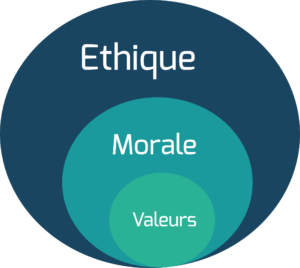
L’éthique peut être définie comme une discipline philosophique portant sur les jugements moraux. Elle permet l’établissement des normes, limites et devoirs d’un peuple.
En suivant cette définition, l’éthique apparaît comme étant le pendant moral de la législation. Elle permet de cadrer les actions d’une population, en définissant ce qui doit être fait ou non, ce qui est acceptable et ce qui ne l’est pas. Toutefois, ne faisant pas loi, l’éthique ne trouve pas d’application législative et juridique, mais elle permet de soulever des débats pour faire évoluer ce cadre.
En parallèle, la morale comprend l’ensemble des valeurs et des règles (c’est-à-dire les obligations et interdictions) permettant à divers individus de vivre en société.
Vous l’aurez compris, morale et éthique sont donc deux concepts très proches, mais il existe une légère distinction puisque l’éthique, réflexion fondamentale, servira de support à la morale pour établir ses normes.
Existe-il vraiment une éthique ? Des disparités culturelles à toutes les échelles
Mais existe-il une notion universelle d’éthique ?
Par exemple en France, serait-il acceptable de lancer des expérimentations sur des foetus chimères (mi-humain mi-animal) ? Le Japon vient de les autoriser. Est-il éthique de mettre en place un système de scoring social ? La Chine le met en place. Enfin, est-il normal d’avoir une bonne situation professionnelle ou un compte en banque bien rempli pour avoir accès aux soins ? Cela semble normal pour un habitant des Etats Unis.
Si la conception de l’éthique peut varier d’un individu à un autre, nous allons prendre un peu de recul pour procéder à une analyse plus globale. Et parce que l’IA est soumise à de nombreux intérêts économiques, il est utile de commencer par apporter une vision macro-économique du sujet. Nous allons nous concentrer sur les 3 principaux pôles mondiaux : les Etats-Unis (et plus largement l’Amérique du Nord), la Chine et l’Europe.
De manière générale, et en ce qui concerne l’IA, les Etats-Unis suivent une stratégie expansionniste via les GAFA et NATU. La vision américaine consiste à développer des sociétés et solutions à vocation internationale. Si la recherche publique contribue amplement aux avancées technologiques, c’est principalement par les sociétés privées multinationales que se développe l’intelligence artificielle américaine. Mais la vision américaine se caractérise également par sa dimension ultra libérale. Les sociétés peuvent avancer rapidement sans rencontrer d’embûches.
A priori, la Chine suit le même schéma puisque les BATX s’érigent comme les locomotives de l’IA chinoise. Toutefois, il existe de nombreuses différences. Tout d’abord, le gouvernement chinois est très influent et oriente les stratégies des sociétés privées. De plus, d’un point de vue marché, les géants chinois se développent avant tout sur leur territoire – plutôt logique lorsque l’on connaît la taille du marché intérieur. Et, les technologies développées localement sont donc déployées et utilisées au niveau national. Un facteur aide également à faciliter les expérimentations : le caractère autoritaire du gouvernement. En atteste la mise en place d’un vaste réseau de caméras de surveillance couplé à une technologie de reconnaissance faciale. Un tel déploiement en Europe serait inimaginable.
Ensuite, en ce qui concerne l’Europe et l’intelligence artificielle, nous sommes un peu à la traîne. Mais est-ce un mal ? Pas tout à fait. Si la recherche publique est encore très puissante sur le Vieux Continent, ce qui caractérise l’Europe, c’est avant tout son positionnement vis à vis de l’IA. L’Union Européenne défend l’idée de développer une IA éthique, une IA respectueuse de l’humain et de ses droits fondamentaux. Toutefois, cela peut poser plusieurs problèmes. Premièrement, l’UE prône une IA éthique mais nous avons vu que l’éthique et ses composantes varient beaucoup, les stratégies chinoises et américaines correspondent à leur propre vision de l’éthique. Deuxièmement, pendant que l’Europe tergiverse et se questionne sur de potentielles dérives et conséquences néfastes, elle ne développe pas l’IA.
Enfin, les disparités se retrouvent à un niveau bien plus bas. L’éthique et l’idée que l’on s’en fait divergent au sein même des pays et entre les sociétés elles-même. Par exemple, de nombreuses sociétés spécialisées en IA travaillent sur des projets militaires. Pour ces entreprises, intégrer de l’IA dans une arme ne pose pas de problème éthique. A contrario, Neovision se refuse par exemple à travailler sur cette typologie de projet, pour une question d’éthique.
Une réglementation au service de l’éthique ?
Des lois officielles
L’éthique est rattachée à de nombreux concepts : morale, valeurs, principes ou encore des règles. Cette dernière notion est celle qui se rapproche le plus de l’action, du concret. Dans notre société, ces règles prennent plusieurs formes et notamment celle de lois.
Nous nous intéresserons ici aux législations françaises et européennes qui impactent la recherche et le développement de l’IA sur le territoire, la protection de la vie privée et des données personnelles et une utilisation encadrée de l’IA.
Le 6 janvier 1978 été adoptée la loi Informatique et Libertés (avec une nouvelle rédaction en 2019). Elle vise à “réguler la liberté de traitement des données personnelles, c’est-à-dire la liberté de ficher les personnes humaines”. Plus concrètement, une société privée n’a pas le droit d’exploiter vos données personnelles sans avoir obtenu votre consentement.
Cette loi déboucha sur la CNIL (Commission Nationale de l’Informatique et des Libertés), une autorité administrative indépendante française chargée d’assurer la protection des données personnelles, tant dans le domaine privé que public.
Le 14 avril 2016, la loi Informatique et Libertés trouvait un écho européen avec le Règlement Général sur la Protection des Données (RGPD). Concrètement, le RGPD reprend les mêmes idées que défend la CNIL tout en s’appliquant à l’ensemble des pays membres. Le but était d’uniformiser la protection des données personnelles au niveau européen pour éviter toute disparité au sein de l’UE.
Des règles officieuses et différentes recommandations
À défaut de lois plus strictes, nombre d’organisations ont publié des guidelines, c’est-à-dire des listes de règles à suivre pour mener à la création d’une IA éthique. Par exemple, les USA, l’UE et la Chine ont émis des guidelines de leur côté (respectivement “Report on the Future of AI, “Ethics Guidelines for Trustworthy AI” et “Beijing AI Principles”). De même, Google, Deep Mind ou Microsoft ont publié une liste de principes internes.
Mais les ambitions de ces propositions sont critiquables (The Ethics of AI Ethics : An Evaluation of Guidelines, Hagendorff). En premier lieu, elles n’ont aucun caractère contraignant. Pire on pourrait considérer pour certaines organisations qu’il s’agit d’un moyen de soigner son image sans remettre en cause ses pratiques. Surtout, peut-on vraiment espérer de véritables régulations efficaces si ces dernières sont décidées par les acteurs même qui bénéficieraient d’un manque de règles ?
En plus de cela, beaucoup de guidelines se focalisent sur des aspects purement techniques qui, s’ils sont importants, sont déjà abordés par la communauté. Les impacts potentiellement néfastes de ces technologies sur la société sont, en comparaison, peu traités.

Enfin on peut questionner l’efficacité de ce genre de guidelines. En pratique, une étude (Does ACM’s Code of Ethics Change Ethical Decision Making in Software Development ?, McNamara et al.) a montré qu’il n’y avait pas de différences significatives dans le comportement d’ingénieurs et développeurs conscients de ce genre de guidelines. La faute à des principes globaux trop larges qui ne rentrent pas dans les détails de leur mise en oeuvre.
Les problématiques propres à l’IA
La question des données
L’apprentissage automatique, en particulier sur des réseaux de neurones profonds, est très dépendant de la qualité des données qu’il utilise. Le réseau ne fait en fait que “reproduire” un modèle statistique des données.
Une des plus grosses contraintes est souvent de pouvoir qualifier les données. Par exemple, pour pouvoir distinguer un chat d’un chien, une IA a d’abord besoin qu’on lui précise ce qu’est un chat et ce qu’est un chien. C’est ce qu’on appelle l’annotation des données et celle-ci nécessite très majoritairement une intervention humaine.
Pour les tâches les plus complexes, il peut s’agir d’un travail ouvrier fastidieux pour lequel sont souvent utilisés des plateformes de crowdsourcing telles que Amazon Mechanical Turk. Elles s’appuient sur des travailleurs indépendants rémunérés à la tâche, peu protégés et mal payés (pas de salaire minimum). Or on estime que pour 25% des utilisateurs de MTurk il s’agit de leur source de revenu principale (Responsible research with crowds: pay crowdworkers at least minimum wage, Silberman et al.). Ces travailleurs ne sont souvent pas considérés comme de réels participants au résultat final.
Parlons des biais maintenant. Puisqu’un modèle d’IA est un modèle statistique des données, il reproduit les biais qui s’y trouvent. Les technologies de reconnaissance faciale par exemple ont plusieurs fois été épinglées pour ce genre de problèmes. Des chercheuses du MIT ont publié en 2018 un étude appelée Gender Shades qui tentaient de mettre en lumière ces biais dans des modèles de reconnaissances faciales populaires (Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification, Bualamwini et al.). Elles ont montré que les technologies de Microsoft, IBM et Legvii pouvaient être jusqu’à 34% moins performantes pour des femmes noires que pour des hommes blancs. Similairement, les modèles de langues utilisés en traitement du langage naturel reproduisent les biais présents à la fois dans les textes d’origines ainsi que ceux résultant du choix de ces textes (Language (Technology) is Power: A Critical Survey of “Bias” in NLP, Blodgett et al.).
De manière générale, on court le risque de créer des modèles qui sont particulièrement adaptés aux représentations dominantes des pays qui les produisent. On peut donc se poser la question, notamment pour les applications médicales, du risque de créer des technologies qui marcheront mieux sur les blancs des pays riches que sur d’autres populations.
Manque de transparence & inexplicabilité
La notion de transparence en IA est un concept assez large qui fait aussi bien référence au manque d’explicabilité des prédictions issues des modèles d’intelligence artificielle qu’à la transparence des données et du code.
La complexité de certains modèles de deep learning par exemple fait qu’il n’est pas aisé de retracer le processus qui a mené à la prise de décision. On parle même assez souvent (à tort et à raison) de “boîte noire”. Alors que l’imaginaire collectif est déjà peuplé de cette crainte d’une IA qui déciderait par elle-même et échapperait au contrôle de ses créateurs, ce manque d’explicabilité rend plus difficile l’acceptation d’IA dans la vie de tous les jours. Ce problème est néanmoins déjà abordé techniquement par la communauté IA. Une telle transparence sera sans doute nécessaire pour accroître la confiance du public dans ces technologies. Ceci est d’autant plus vrai que de plus en plus de décisions risquent d’être confiées à des modèles d’intelligence artificielle.
Mais il y aussi des aspects de transparence des données et des codes sources. L’IA représente aujourd’hui un secteur économique important avec un enjeu concurrentiel clair. De ce fait, il y a fort à parier que la demande de transparence de ces technologies aille contre les intérêts de puissances économiques et politiques. Il est aussi à noter qu’un système entièrement explicable ouvre la porte à la possibilité de le duper de manière malveillante. Enfin, il existe aussi un risque pour la protection de la vie privée dans l’utilisation de données.
Vides juridiques
Autre problématique liée à l’intelligence artificielle, ainsi qu’aux autres innovations de rupture : les vides juridiques. Un vide juridique, c’est l’absence de loi ou de normes applicables à une situation spécifique. Or, avec le développement de l’IA, les situations inédites et spécifiques se multiplient et cela bien plus vite que les lois permettant de les encadrer.
Toute personne s’intéressant de près ou de loin au sujet s’est posé la question du dilemme moral. Vous êtes au volant de votre véhicule autonome et le pilote automatique est activé. Tout à coup, surgit de nulle part un enfant, sur votre droite, un précipice, à votre gauche un véhicule transportant une famille complète. Face à ce dilemme, qui rappelle celui du tramway, les réactions sont très différentes et aucun consensus éthique n’a encore été trouvé. Le MIT a créé un site web, Morale Machine, permettant d’étudier les réactions des internautes (https://www.moralmachine.net/hl/fr). Un exercice particulièrement complexe.
Aujourd’hui, une intelligence artificielle ne dispose d’aucune responsabilité juridique, et nous pouvons le comprendre tant les réponses actuelles n’apportent pas satisfaction. La question reste donc pour l’instant entière et en suspens.
Neutralité technologique mais de bonnes et de mauvaises applications
Toute technologie peut évidemment mener à de mauvaises applications. La question se pose néanmoins dans le cas de l’IA en regard de la multitude de domaines dans lesquels elle est utilisée ainsi que de la relative méconnaissance de son fonctionnement.
L’utilisation de la reconnaissance faciale par exemple représente un vrai risque pour la vie privée des personnes. Que ce soit pour la surveillance de la part de gouvernement, la revente de données pour des entreprises ou l’obtention d’informations sur une personne croisée dans la rue. Il existe de plus un optimisme naïf à propos de leurs performances alors qu’elles présentent un risque de reproduire des inégalités de part leurs biais. D’ailleurs, la ville de San Francisco a décidé de bannir l’utilisation de logiciel de reconnaissance faciale, notamment pour sa police. Et, pour des raisons similaires, IBM a choisi de se retirer du marché de la reconnaissance faciale. Plus proche de nous, en France, nous pouvons citer l’application Alicem, qui nous permettra d’accéder aux services administratifs suite à un scan de notre visage.
La performance de certains modèles d’IA déjà déployés est de plus parfois largement surestimée. Le logiciel COMPAS par exemple, utilisé par le système judiciaire américain pour prédire la probabilité de récidive d’un accusé, ne serait pas meilleur que l’avis de personnes aléatoires selon une récente étude (The accuracy, fairness, and limits of predicting recidivism, Dressell et al.).
Certains s’inquiètent aussi de l’utilisation des capacités de prédiction de ces modèles pour remettre à jour des théories proches de la physiognomonie ( (https://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a), c’est-à-dire l’utilisation de traits physiques pour prédire des comportements. Par exemple, les auteurs d’un article paru en 2017 prétendaient que leur modèle détectait l’orientation sexuelle de personnes à partir de traits du visage. En réalité, de part le contexte des données (qui venaient d’un site de rencontre), il s’est avéré que l’algorithme se basait bien plus sur les normes sociales entourant la prise de photos.

L’intelligence artificielle peut aussi être utilisée pour influencer le comportement des utilisateurs (Persuasive Technology: Using Computers to Change What We Think and Do, Fogg 2003). Un exemple récent est le scandale autour de Cambridge Analytica, qui se servait des données récupérées sur Facebook dans le but de faire des publicités politiques ciblées en faveur du Brexit puis de l’élection de Donald Trump.
Mais les recommandations personnalisées questionnent aussi le libre arbitre. Spotify, Youtube, Netflix, Amazon ou encore Google nous mâchent le travail et nous proposent du contenu censé nous plaire. Sauf que, comme l’a théorisé Eli Pariser avec l’idée de chambres d’écho (Pariser 2011), ces technologies de personnalisations peuvent petit à petit nous isoler de certaines informations et donc nous enfermer culturellement et socialement.
Des technologies qui ont un vrai coût environnemental
Les modèles les plus développés d’intelligence artificielle, et les modèles de deep learning en particulier, nécessitent d’importantes puissances de calcul, notamment pendant l’entraînement. Mais nous ne pouvons aujourd’hui décemment plus ignorer les coûts environnementaux des activités humaines dans le cadre de l’éthique.
En 2019, des chercheurs ont étudié les coûts en énergie pour l’entraînement de quelques modèles les plus récents en NLP, la discipline se rapportant au traitement du langage naturel, où sont régulièrement utilisés des modèles de taille particulièrement importante. Leurs résultats montrent que l’entraînement complet d’un modèle (ici un modèle à l’état de l’art appelé BERT) équivaut au même impact environnemental en termes d’émissions de CO2 qu’un voyage en avion aller-retour entre New York et San Francisco. En outre, on ne parle ici que du temps nécessaire à l’entraînement final d’un modèle. En réalité, le travail de R&D derrière le développement d’un nouveau modèle nécessite de nombreux entraînements avant de trouver le plus performant.
Les solutions à ce problème sont complexes et la question se pose évidemment pour de nombreuses technologies en dehors du domaine de l’intelligence artificielle. Mais il est nécessaire de se poser la question de l’utilisation des ressources énergétiques dans le cadre de l’IA.
Microsoft s’est récemment séparé des journalistes responsables de la mise en avant des informations sur les pages d’accueil de MSN et Microsoft Edge. À la place, l’entreprise se sert de technologies d’intelligence artificielle pour automatiquement sélectionner et mettre en forme le contenu qui sera affiché. Et si les journalistes n’imaginaient pas forcément faire parti des catégories dont le travail pourrait être remplacé par une IA, certains métiers, comme celui d’hôte de caisse, subissent depuis plus longtemps les effets de la robotisation de leur métier.
Coût sociétal : “They took our jobs !”
Ceci pose évidemment d’abord le problème, dans des sociétés à fort taux de chômage, de l’emploi des personnes dont le travail a été remplacé. Et si il peut être avancé qu’il s’agit de tâches ingrates et répétitives qu’il est donc préférable de confier à une machine, le fait est que les personnes dont c’était jusqu’alors l’emploi se retrouvent sans salaire. Un argument souvent avancé est que le développement du secteur de l’intelligence artificielle permettrait la création de nouveaux métiers dont le nombre compenserait ceux perdus. Même si ceci était vrai (https://www.livemint.com/technology/tech-news/-more-jobs-will-be-created-than-are-lost-from-the-ai-revolution-wef-ai-head-11570190160812.html), il est à noter que les nouveaux emplois ne partagent généralement pas le même niveau de qualification que ceux détruit.
La recherche d’automatisation enlève aussi la part d’humain qui peut exister dans certains métiers. Il est à craindre que, dans un but de diminution des coûts, certaines fonctions où un contact humain est important se retrouvent automatisées pour des raisons d’économie (par exemple dans le cas de l’assistance à la personne).

Enfin, dans le cas de Microsoft cité plus haut, automatiser cette fonction peut créer des effets collatéraux qui n’étaient pas forcément envisagés. Par exemple, certains critères appliqués par les journalistes pour leurs choix éditoriaux ne sont pas forcément répliqués par la machine. S’il est en effet facile de mettre en avant des contenus populaires, il est bien plus complexe de s’assurer automatiquement de la visibilité de contenus plus minoritaires ou d’éviter de publier des fake news.
L’IA par et pour la population
Défini par des entreprises ou par des pouvoirs publics
Le développement et le déploiement de l’intelligence artificielle se fait principalement via la mise sur le marché de solutions technologiques. Des technologies qui s’adressent au grand public ou aux professionnels.
Or en amenant une technologie sur le marché, une société privée influence l’éthique générale que peut avoir la population vis à vis de l’IA, ou du moins, elle va confronter une technologie à la population. Toutefois, les applications de l’IA ne sont pas toujours transparentes quant à leur fonctionnement, notamment pour la captation des données et leur exploitation. La technologie se retrouve cachée, encapsulée dans un service. Les assistants vocaux comme Siri ou Alexa par exemple posent plusieurs questions. S’ils apportent une véritable commodité dans la vie de tous les jours, ils captent aussi des données personnelles sans que les utilisateurs ne s’en rendent vraiment compte. Les technologies IA commercialisées vont donc avoir une influence non négligeable sur l’éthique.
Deux autres facteurs peuvent également pousser une population à accepter une nouvelle technologie : le besoin d’appartenance pour le grand public et la pression concurrentielle pour l’économie. Si une majorité de la population utilise une IA native pour améliorer la qualité des photos, il y a fort à parier que les derniers réfractaires prendront le pli. De la même façon, si l’ensemble des sociétés d’un secteur d’activité donné intègre une solution IA leur permettant de booster leurs performances, les retardataires l’intégreront à leur tour pour ne pas perdre leurs parts de marché.
Parallèlement aux sociétés privées, nous retrouvons les pouvoirs publics. Leur influence se concrétise principalement sous la forme de lois et de directives. Si les pouvoirs publics vont souvent dans le sens des initiatives privées aux Etats-Unis et qu’il est difficile de dissocier le public du privé en Chine, la donne est sensiblement différente en Europe.
Les lois européennes semblent avant tout protéger les utilisateurs, une très bonne chose en soi. Pour cela, elles vont venir encadrer le périmètre d’action des technologies basées sur de l’intelligence artificielle. Avec ces mesures, l’Europe et ses institutions protègent leur souveraineté en jugulant des technologies développées loin de son territoire, principalement en Amérique du Nord et en Asie. Cela pourrait permettre à l’Europe de conserver son indépendance et sa souveraineté numérique en boostant le développement de solutions locales.
Cependant, les sociétés européennes se voient obliger de respecter des règles bien plus strictes que leurs concurrents. Ce qui renforce donc les positions actuelles à savoir l’omniprésence des GAFAMI et l’essor des BATX en Europe. Or, nous savons également que nos pouvoirs publics ont énormément de mal à faire appliquer cette éthique et leurs directives aux sociétés américaines et asiatiques. Ils ont notamment peur de représailles économiques d’envergure comme la récente taxe GAFAM le rappelle.
Comment rendre l’IA à la population ?
Nous l’avons déjà expliqué précédemment, la population, dans sa grande majorité, a une perception biaisée de ce qu’est réellement l’IA, de ses rouages mais aussi de ses impacts. Toutefois, le peuple devrait être en mesure d’orienter le développement et les usages de ces technologies. Mais pour cela, elle doit d’abord savoir ce qu’est concrètement l’IA.
La vulgarisation scientifique
Or, pour permettre au grand public de comprendre les tenants et les aboutissants de l’intelligence artificielle, il est nécessaire de rendre cette discipline scientifique et ces technologies accessibles et compréhensibles par tout le monde. Un discours vulgarisé donne donc l’opportunité à chacun de se construire un regard critique sur le sujet.
Si vous souhaitez mieux comprendre l’intérêt de la vulgarisation dans la diffusion des innovations, n’hésitez pas à aller consulter notre premier podcast qui y est consacré !
Sensibiliser ingénieurs et chercheurs
Il est aussi nécessaire que la prise en compte de l’éthique vienne de l’intérieur de la profession. Une pression venant de l’intérieur peut permettre de forcer les entreprises à revoir leur politique éthique indépendamment des considérations économiques. Le projet militaire Maven a par exemple été abandonné par Google après des protestations des employé·es. De la même façon, des employé·es à Microsoft ont protesté contre la collaboration de l’entreprise avec le département du contrôle de l’immigration des Etats-Unis (ICE).
Néanmoins, la prise de conscience est encore lente parmi les acteurs directs du secteur, en partie dû à un manque de sensibilisation des futur·es ingénieur·es et docteur·es. Encore trop peu de formations intègrent des considérations éthiques et le métier n’est enseigné que d’un point de vue purement technique. De plus, le manque de diversité dans la communauté, déjà un problème en soi, implique une homogénéisation des façons de penser. L’éthique est avant tout une discussion qui est enrichie par l’apport de visions différentes.
Il est néanmoins à noter que le secteur tend à changer. Outre les différents comités éthiques mis en place dans de grandes entreprises, dont on peut néanmoins douter du pouvoir d’action, le milieu académique se saisit aussi du sujet. NeurIPS par exemple, une conférence majeure dans le domaine, impose aux auteurs l’ajout d’une déclaration sur les potentiels impacts sociaux des travaux publiés.
Notre charte éthique : une preuve d’engagement
Concrètement, en l’absence de législation spécifique à l’IA, l’éthique se construit brique par brique, par les concepteurs et les usagers. Au final, ce sont eux qui définissent, de manière macro, ce qui est éthique ou non. Certaines sociétés se lanceront dans des projets que d’autres refuseront, et des utilisateurs se jetteront sur des applications que d’autres verront comme dangereuses.
A Neovision, nous pensons que l’éthique globale se définira de cette façon, c’est pourquoi nous avons décidé d’inscrire nos valeurs au travers d’une charte éthique. Cette dernière nous permet d’expliciter ce que nous souhaitons faire, et ce que nous nous refuserons à faire. Le tout en détaillant l’ambition de la société et les modalités selon lesquelles nous chercherons à atteindre nos objectifs. Nous pensons que l’IA doit être développée dans l’unique objectif de servir l’humain et que l’inverse ne soit vrai que dans des fictions.
Si vous souhaitez en savoir plus sur notre charte éthique vous pouvez la retrouver ici : Charte éthique Neovision
Conclusion
“Science sans conscience n’est que ruine de l’âme” écrivait Rabelais. Comme pour tout domaine scientifique, l’éthique doit avoir un rôle central dans le développement technologique. Si nous croyons en la neutralité de la technologie, il n’en va pas de même avec l’Homme. Et c’est bien là que le bât blesse. Si l’IA permet de développer des solutions vertueuses, ces dernières peuvent également être détournées pour servir des desseins bien moins nobles.
Toutefois, nous avons aussi vu qu’aucun consensus n’avait été trouvé quant à l’éthique et que de fortes disparités existent à tous les niveaux.
La question est complexe et reste à ce jour sans réponse. Mais l’objectif semble clair : remettre les citoyens au centre du débat et engager un vrai dialogue pour éviter des dérives sociales, économiques et géopolitiques.