
IA COGNITO – EP03 – Le Machine Learning
Dans l’épisode d’aujourd’hui, nous nous intéressons à LA branche de l’intelligence artificielle qui a le vent en poupe ces 10 dernières années : le Machine Learning, ou l’apprentissage automatique comme dirait Molière. Au menu du jour : focus sur les grandes étapes du Machine Learning et présentation des différents types d’apprentissages existants.
Le Machine Learning
Synthèse introductive
Lorsque l’on évoque l’IA, on fait rapidement le parallèle avec le Machine Learning. Théorisé au milieu du XXème siècle, de consort avec le concept d’intelligence artificielle, il a été utilisé jusqu’à la fin des années 90 comme une méthode d’IA parmi d’autres.
Au début des années 90, les progrès dans le hardware et l’explosion des puissances de calcul coïncident avec l’essor de nouvelles techniques de Machine Learning. A cela s’ajoute l’essor d’internet et la disponibilité croissante de données à exploiter. Toutefois, si la puissance de calcul est désormais décuplée, peu d’acteurs ont la capacité de s’équiper de machines puissantes. Celles-ci restent trop onéreuses. C’est alors qu’apparaissent les acteurs du cloud, donnant l’accès à une grande puissance de calcul grâce à des serveurs déportés.
Toutes les conditions sont alors réunies pour que le Machine Learning se développe : puissance de calcul décuplée, serveurs et machines virtuelles accessibles et volume de données croissant.
Maintenant que nous en savons un peu plus sur le Machine Learning et son histoire, intéressons nous à son fonctionnement et aux deux grandes phases du Machine learning : l’apprentissage et l’inférence.
Apprentissage et Inférence
Le Machine Learning, ou apprentissage automatique donc, se décompose en deux grandes phases : l’apprentissage et l’inférence.
La première, l’apprentissage, permet de “calibrer” et “créer” un modèle d’intelligence artificielle en apprenant sur un grand volume de données tandis que la seconde, l’inférence, correspond à l’utilisation d’une IA. L’inférence va faire une prédiction, une analyse portée sur une nouvelle donnée.
Pour en revenir à l’apprentissage, ce dernier se fait étape par étape et cela commence toujours par une préparation des données.
L’Apprentissage
Catégoriser son problème
La première chose à faire est de correctement expliciter le problème que nous cherchons à résoudre. Ce dernier doit être catégorisé via des variables d’entrée et de sortie.
L’apprentissage supervisé permet de répondre à deux types de questions :
- Classification : “Qu’est ce que c’est ?”
- Régression : “Quelle est sa valeur ?”
Prenons des photos de pommes. Admettons que vous avez plusieurs pommes sur vos photos. Vous pouvez les compter ou bien les classifier par variété.
Si vous souhaitez détecter les pommes, vous êtes face à une problématique de régression. Lors de l’annotation (une étape de la préparation des données que nous verrons juste après), vous n’indiquerez pas la variété ou simplement la présence mais la position d’une pomme sur l’image. Votre variable d’entrée sera donc une image et votre variable de sortie sera une prédiction, portant sur la position (ou non) de pommes.
Si vous souhaitez différencier les différentes espèces de pommes, vous êtes face à une problématique de classification. Lors de l’annotation, vous indiquerez la variété de la pomme, c’est ce que vous souhaitez prédire. Ainsi, votre variable d’entrée sera toujours une image, mais votre variable de sortie sera une classification selon les variétés de pommes.
Il faut ensuite choisir le type d’apprentissage le plus adapté : apprentissage supervisé, non-supervisé ou par renforcement. Pour vous expliquer l’apprentissage, nous nous concentrerons sur l’apprentissage supervisé. Les autres seront traités à la fin de cet épisode.
L’apprentissage se fait sur un grand nombre de données. L’algorithme d’apprentissage va apprendre en analysant ces données et leurs caractéristiques. Pour illustrer cela, prenons l’exemple suivant : si nous voulons qu’un jeune enfant apprenne à quoi ressemble une pomme, nous lui en montrerons beaucoup et nous lui répèterons à chaque fois que c’est une pomme.
Préparer son jeu de données
Avoir des données de qualité, et en quantité, c’est bien. Mais ce n’est malheureusement pas suffisant. Celles-ci doivent être structurées et nettoyées. Le nettoyage des données consiste à détecter les données manquantes, doublons et autres outliers (des données aberrantes et non représentatives). Ces données problématiques devront être corrigées ou supprimées.
Concernant la structuration des données, il s’agit surtout de mettre en forme et transformer les données.
Vos données nettoyées et structurées, vous pouvez maintenant les annoter. Une tâche aussi fastidieuse qu’essentielle. L’annotation correspond au fait d’ajouter de l’information à une donnée pour la qualifier. Par exemple, lier le mot chat à chaque photo de chat. Le mot chat correspond à l’annotation.
Prenons l’exemple d’une entreprise souhaitant concevoir et développer une IA. Ses données internes, ce sont celles qu’elle a capté elle-même, issues de son activité. Elles sont essentielles mais pas toujours suffisantes. Sur certains projets, elles devront être enrichies. Enrichir son jeu de données, cela consiste à ajouter de nouvelles données, externes, susceptibles d’améliorer votre modèle. Il peut s’agir de données météorologiques, financières, économiques, démographiques… Des données caractérisant un événement ou phénomènes impactant directement ce que vous essayez de prédire. Les données externes peuvent être accessibles et gratuites, (données publiques, Open Data) ou pas (données captées par des entreprises).

Après cette étape, les données ne sont pas encore forcément utilisables pour l’apprentissage. Elles peuvent par exemple contenir trop d’informations non pertinentes. C’est pour ça qu’il faut en extraire des caractéristiques discriminantes, ce qu’on appelle des features.
Extraire les features
Avant de lancer l’entraînement, vous devrez donc extraire les features, ou caractéristiques en français.
Pour expliquer ce qu’est une feature, prenons le parallèle des statistiques. Un statisticien analyse une population, un data scientist s’intéressera à un dataset. Dans la population, chaque individu est vu comme une unité, dans le jeu de données, nous appellerons chaque unité une observation, ou une donnée. Enfin, pour chaque individu d’une population, nous avons des variables qui le caractérisent (nom, âge, sexe, etc.). Il en va de même pour chaque observation du dataset et ces variables caractéristiques sont appelées features.
Reprenons l’exemple des pommes. Le jeu de données, ce sont des pommes de multiples variétés. Une donnée, c’est une pomme d’une variété précise et les features correspondent à ces caractéristiques : couleur, taille, acidité, taux de sucre, etc.
Il s’agit donc d’extraire les caractéristiques les plus discriminantes pour une donnée, une information la caractérisant de manière marquée.
Les caractéristiques sont très variables, d’un jeu de données à un autre mais aussi en fonction de la tâche que l’on souhaite que l’IA accomplisse.
Sur une image, par exemple, les features intéressantes peuvent être les couleurs, les formes ou les textures. Par exemple, pour classifier plusieurs espèces de pommes, la couleur sera une caractéristique discriminante, la forme beaucoup moins puisque toutes les pommes sont plutôt rondes. Un constat non généralisable, si nous cherchons à classifier des chats ou des chiens, un chat et un chien pouvant être de la même couleur.
Ces features seront ensuite liées aux annotations ce qui permettra de caractériser une donnée. Prenons l’exemple d’une photo de pomme. L’annotation dira “pomme Pink Lady” et les features pourraient être sa couleur un mix de jaune, rouge et rose, et sa taille moyenne.
En vision par ordinateur, il existe différentes techniques, utilisables en amont de l’apprentissage, permettant de détecter les features. Une des plus connues est par exemple celle des descripteurs SIFT (Scale-Invariant Feature Transform).
Choisir l’algorithme
Maintenant que nous avons correctement préparé nos données et que nous avons extrait les caractéristiques les plus discriminantes, nous rentrons concrètement dans l’apprentissage.
Vient maintenant le temps de trouver votre algorithme d’apprentissage supervisé adapté. De nombreux algorithmes existent, dessinant un compromis entre complexité et performances. Parmi les plus connus, on peut citer les machines à vecteur de support (SVM), les random forests ou les K plus proches voisins.
L’entraînement
Vous avez maintenant des données de qualité, en quantité suffisante, bien structurées, annotées et même enrichies ! Vous avez même extrait les features de vos données et caractérisé la problématique que vous souhaitez traiter. Il n’y a plus qu’à, me direz vous.
Que nenni, il faut encore découper et répartir ce jeu de données. En général, 80% des données seront utilisées pour l’apprentissage et les 20% restant serviront à tester et valider les performances de l’apprentissage. Il est également commun de séparer le jeu de validation du jeu de test.
Comme nous l’avons vu juste avant, il existe de nombreux algorithmes et chacun d’eux dispose de ses propres règles et paramètres.
Un apprentissage va avoir pour but d’optimiser les paramètres d’un modèle. Pour cela, l’algorithme d’apprentissage va “regarder” la base de données et paramétrer le modèle grâce aux données observées. Le but du modèle est d’être capable d’effectuer des prédictions correctes.
Le modèle est ensuite testé sur le jeu de données de test (logique) et il sera conservé si les résultats sont convaincants. Si ce n’est pas le cas, les paramètres doivent être ajustés pour trouver la meilleure combinaison possible.
En plus des paramètres du modèle, il y a des paramètres “réglés” par l’humain et qui décident de la façon dont l’algorithme va apprendre. On peut par exemple tout simplement citer le nombre d’époques pendant lesquelles l’algorithme va apprendre. On appelle ceux-ci des hyperparamètres. De nombreuses combinaisons d’hyperparamètres doivent être testées, et bien entendu, faire cela à la main prendrait un temps fou. Communément, les data scientists ont recours à diverses méthodes pour tester automatiquement les combinaisons les plus pertinentes.
Lors des tests et de la validation du modèle, il faut porter une attention particulière au sur-apprentissage (overfitting) et au sous-apprentissage (underfitting).
L’overfitting signifie que le modèle est trop spécialisé sur les données du jeu d’entraînement. Il a appris par coeur ces données plutôt que d’en tirer une représentation générale. Il n’aura donc pas de bonnes performances sur les données des jeux de test et de validation. Toujours avec notre exemple de pomme, un modèle souffrant de sur-apprentissage pourrait ne reconnaître que des pommes ayant une forme et une couleur précise. Tout le reste ne serait pas reconnu comme étant une pomme.

Pour l’underfitting, le modèle ne se généralise pas et ne fonctionne pas non plus sur le jeu d’entraînement. C’est notamment le cas lorsque les résultats d’un modèle ne prennent pas en compte les features pertinentes pour la tâche à accomplir. Par exemple, ce serait le cas pour un modèle visant à prédire le prix d’un appartement en ne prenant en compte que la superficie.
L’Inférence
Le gros morceau de l’apprentissage est passé. Vous disposez d’un modèle performant car bien entraîné, testé et validé. Du moins sur les jeux de données que vous aviez en votre possession. Est maintenant venu le temps de l’inférence *musique céleste* !
L’inférence, c’est lorsque vous proposez une nouvelle donnée à votre modèle pour qu’il la traite et propose sa prédiction.
Il s’agit du moment où l’on teste vraiment le modèle, en conditions réelles. En général, cela intervient lors du développement d’un prototype ou d’une mise en production.
Par exemple, si vous utilisez l’application Wine Advisor et que vous vous en servez pour reconnaître une bouteille de vin, vous réalisez une inférence lorsque que vous faites analyser la photo. Le modèle a été entraîné et aujourd’hui il vous donne ses résultats. L’idée est la même lorsque vous reconnaissez une oeuvre de street-art via notre application mobile.
Là aussi, il faut surveiller les performances du modèle. Pourquoi ? Parce que les conditions réelles coïncident avec un environnement bien moins maîtrisé qu’un poste de travail dans une société ou un laboratoire.
Les données présentées au modèle lors de l’inférence peuvent être légèrement différentes des données d’entraînement et augmentent donc le périmètre fonctionnel du modèle.
C’est là que l’on comprend pourquoi le caractère représentatif du jeu de données et la qualité de l’entraînement sont si importants.
Un jeu de données non représentatif, c’est la garantie de voir le modèle rencontrer des données lui semblant aberrantes durant l’inférence, car jamais observées durant l’entraînement.
Pour s’assurer des bonnes performances, il existe des indicateurs statistiques aussi robustes qu’efficaces pour évaluer la qualité de l’inférence. Rapide présentation.
Avant de commencer, il est judicieux d’expliquer ce que sont les vrais positifs, les vrais négatifs, faux positifs et faux négatifs. Pas facile à suivre, n’est ce pas ?
Prenons l’exemple d’un classifieur de chats – les revoilà. La classe “Chat” est donc la classe positive, et “Pas de chat” est la classe négative. On observe une vidéo. Si un chat y est présent, c’est un positif, sinon c’est un négatif. Ensuite si la prédiction du modèle est correcte, on dit que c’est vrai (positif ou négatif) et sinon que c’est faux.
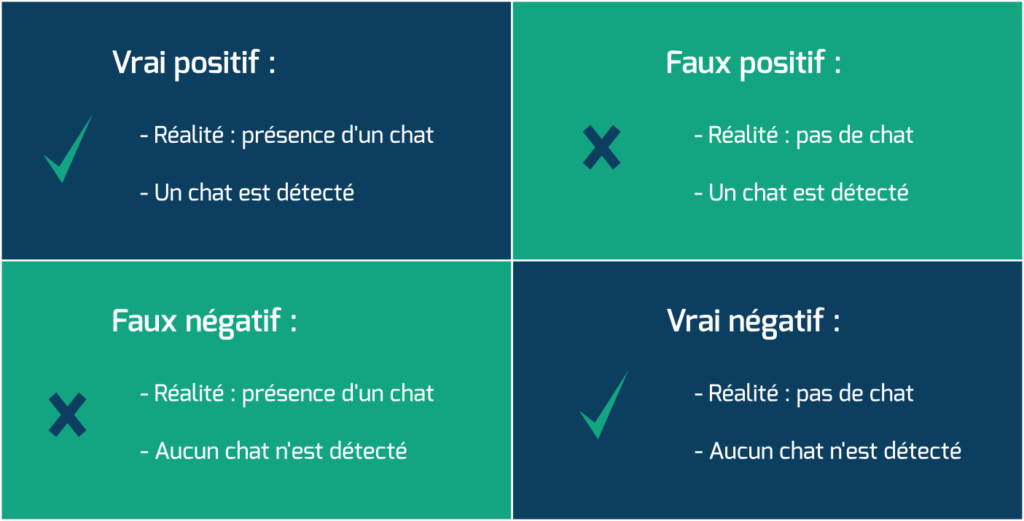
Ces indicateurs permettent alors de calculer la précision et le rappel.
La Précision, c’est un indicateur très utile pour les modèles de classification. Il permet de calculer la proportion du modèle à dire vrai lorsqu’il prédit un positif. Plus elle est élevée, mieux c’est.
Le Rappel, ou Recall, ou Sensibilité, ou taux de Vrais Positifs. Il s’agit là encore d’un indicateur relatif aux classifieurs. Si on reprend nos chats, cela permet de répondre à la question : “Sur toutes les vidéos présentant un chat, combien de fois le modèle l’a-t-il reconnu ?” ou alors “Quelle est la probabilité que le test soit positif si j’ai réellement la Covid ?”
Enfin un indicateur pour la détection : Intersection Over Union ! Lorsque l’on détecte un objet sur une image, un chat par exemple, les modèles de détection vont essayer d’englober le chat dans une boîte. C’est à dire que le modèle va délimiter la zone – appelée boîte – de l’image où se trouve le chat. Toutefois, cette boîte prédite ne correspond pas toujours à 100% avec la réalité terrain, c’est à dire la boîte que dessinerait un humain.
Le but est donc de calculer l’aire de la zone sur laquelle les deux boîtes coïncident par rapport à l’aire totale de l’union des deux boîtes. Plus cet indice est élevé, et donc proche de 1, mieux c’est !

Venons en enfin à la Matrice de confusion : un tableau qui permet de visualiser la qualité des prédictions d’un modèle de classification. Le premier axe correspond à la prédiction du modèle et l’autre axe à la réalité du terrain.
Ici la matrice montre que pour les 14 vidéos où l’on peut réellement voir un chat, le modèle l’a correctement analysé 13 fois (cela correspond donc au rappel). Et sur les 41 vidéos ne présentant aucun chat, il ne s’est trompé qu’une seule fois.

Différents types d’apprentissages
On vous a parlé un peu plus tôt d’apprentissage supervisé. Mais vous avez aussi entendu parler d’apprentissage non-supervisé voire même d’apprentissage par renforcement. Il est donc important d’expliquer clairement la distinction entre ces catégories d’apprentissage automatique.
La différence se joue essentiellement sur la nature et, surtout, la contextualisation des données. Dans le cas de l’apprentissage supervisé, on dispose de données annotées, c’est-à-dire qu’on a rajouté de l’information supplémentaire sur ces données pour les “expliquer” à l’algorithme. En comparaison, lorsqu’on utilise de l’apprentissage non-supervisé, les données seront fournies sans information quant à leur nature, c’est-à-dire sans annotations.
Prenons un exemple classique : on veut un algorithme capable de distinguer les chiens des chats. On va donc pour ça lui montrer un grand nombre de photos et de chats et de chiens. Dans le cas d’un algorithme supervisé, on va préciser à l’algorithme qu’est-ce qui, parmi ces photos, est effectivement un chat et un chien. Sans supervision, et donc sans annotation, on veut idéalement que l’algorithme apprenne de lui-même à séparer au mieux les photos en plusieurs catégories, sans qu’il ne sache ce que représentent ces catégories. L’algorithme tente de comprendre les différences et similitudes entre les photos. Les catégories finales trouvées par l’algorithme pourraient donc aussi bien correspondre pour nous à une séparation entre les chiens et les chats qu’entre les petits et grands quadrupèdes.
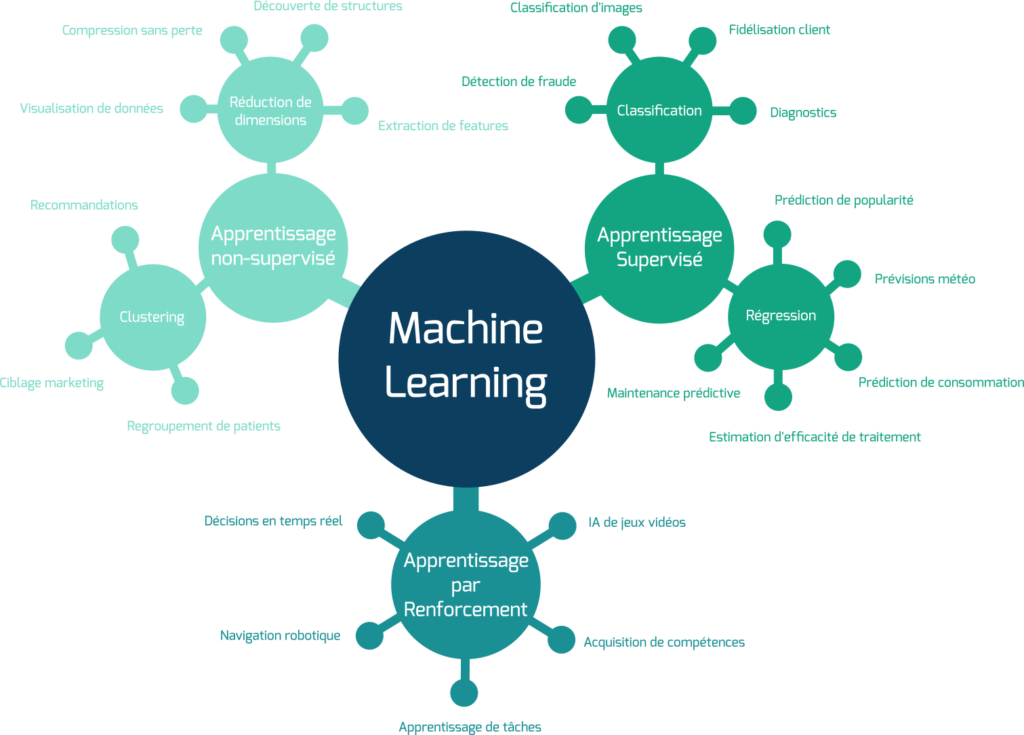
L’avantage évident des algorithmes non-supervisé est donc qu’ils ne nécessitent pas d’annoter les données, une tâche coûteuse, longue, peu intéressante et soumise à de nombreuses erreurs humaines. En contrepartie, il est plus simple d’obtenir un modèle adapté à notre besoin avec des algorithmes supervisés.
Et l’apprentissage par renforcement dans tout ça ? Cette troisième catégorie est très différente des deux précédentes et ne connaît pas une utilisation aussi répandue. Un algorithme d’apprentissage par renforcement est basé sur le principe de récompense : l’algorithme prend une décision et on lui fournit une récompense en fonction de sa décision. On répète alors ce processus de très nombreuses fois jusqu’à ce que l’algorithme ait appris à prendre de bonnes décisions. C’est une façon de faire très proche de la façon dont notre cerveau apprend. L’apprentissage par renforcement est très bien adapté pour des problèmes où on s’attend à ce que l’IA soit capable de prendre des décisions dans un environnement complexe, par exemple comme c’est le cas en robotique et pour les voitures autonomes.
Nous espérons que cet épisode vous aura éclairé et que vous aurez compris – dans les grandes lignes – comment fonctionne le machine learning, la branche de l’IA à la mode depuis plusieurs années.
Nous vous invitons à valider vos connaissances acquises via le petit quizz disponible ci-dessous.
De notre côté, nous vous donnons rendez-vous dans un mois pour aborder un sujet qui nous fera plonger dans les profondeurs de l’IA puisque nous nous intéresserons à une branche du Machine Learning : Le Deep Learning.