
GMFNet : fusion multimodale pour la segmentation sémantique grâce au Deep Learning – Papier de recherche présenté à ECCV
GMFNet : fusion multimodale pour la segmentation sémantique grâce au Deep Learning
La voiture autonome, l’infrarouge et le Deep Learning, cette association vous rappelle quelque chose ? Ce n’est pas vraiment étonnant puisque Neovision a déjà travaillé sur le sujet avec Lynred et publié un papier de recherche en 2018.
En 2020, Neovision s’est à nouveau emparé de ce sujet mais avec un nouvel objectif en ligne de mire. Le but étant de dépasser l’état de l’art en proposant une nouvelle méthode de fusion multimodale, baptisée GMFNet. Ce papier, issu des recherches menées par Etienne Balit et Amine Chadli, a été présenté et accepté par ECCV.
Introduction flashback et segmentation sémantique
Lors du projet précédent, nous utilisions deux types d’images (visible et infrarouge) que nous superposions pour créer des images composites sur lesquelles nous utilisions du Deep Learning pour venir détecter des piétons. Si cette méthode apportait de très bons résultats, une problématique subsistait.
En effet, la création des images composites restait compliquée et peu robuste. De ce fait, nos travaux récents se sont portés sur une nouvelle méthode de fusion des images grâce au Deep Learning.
De ce fait, le Deep Learning est maintenant présent tout au long du processus, de la création/fusion des images jusqu’à l’analyse faite sur ces dernières. Et, in fine, la détection de personnes en infrarouge se fait grâce et par le Deep Learning pour choisir la meilleure modalité au meilleur moment en fonction de la zone de l’image
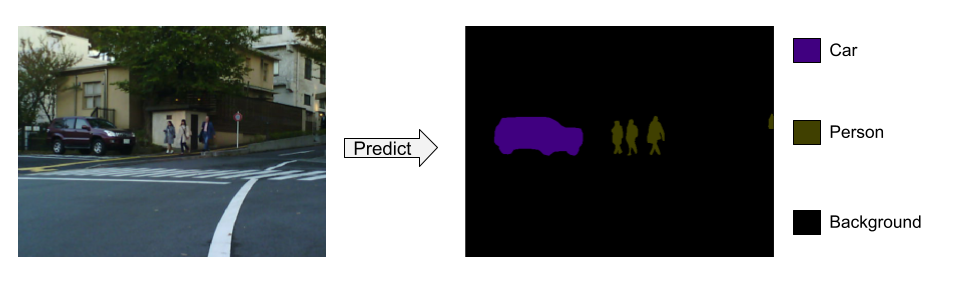
Dans ce nouveau papier, nous étudions la problématique de segmentation sémantique. Cette dernière consiste à attribuer un label à chaque pixel d’une image pour indiquer qu’il appartient à une classe d’objets définie (eg : piéton, voiture, bicyclette…). C’est une tâche primordiale pour de nombreuses applications de conduite autonome, comme la compréhension de la scène, la modélisation de l’environnement et la planification du parcours. En effet, elle permet une compréhension plus profonde de l’image que la détection d’objets.
Petit rappel : pourquoi coupler le domaine du visible et de l’infrarouge ?
Comme nous vous l’expliquions dans notre précédent article, coupler les deux modalités – visible et infrarouge – permet de voir des piétons, quelles que soient les conditions de luminosité.
Or, une perception robuste dans des conditions d’éclairage difficiles est une composante essentielle de la conduite autonome. Et une condition sine qua none dans son développement.
De ce fait, allier caméras visibles et thermiques, qui se sont avérées complémentaires pour la tâche de segmentation sémantique dans des conditions de jour et de nuit, est une voie prometteuse qui mérite d’être creusée.
L’existant, d’où partons-nous ?
Lorsque nous nous intéressons aux approches multimodales, nous nous apercevons que la grande majorité des méthodes à l’état de l’art combinent les caractéristiques des différentes modalités – infrarouge et visible dans notre cas – en proposant une image composite, “superposant” les deux modalités.
Les autres se concentrent sur une concaténation des caractéristiques apprises sur chaque modalité. En somme, très peu de méthodes s’intéressent à l’apprentissage concernant le processus de fusion.
Ce sont ensuite ces images composites qui sont données en entrée à un réseau de neurones multimodal. C’est ce que nous avions fait lors de nos premiers travaux.
Or, une question se pose : que se passe-t-il si l’une des deux modalités présente une défaillance et une partie des informations cruciales n’apparaissent plus à l’image ? Dans le cadre du véhicule autonome et donc de la sécurité routière, cette question prend toute son importance.
Notre proposition
Face à ce constat et fort de notre expérience dans le domaine, nous nous sommes attelés à proposer une solution, une nouvelle approche qui permette de répondre à cette problématique.
Architecture intelligente
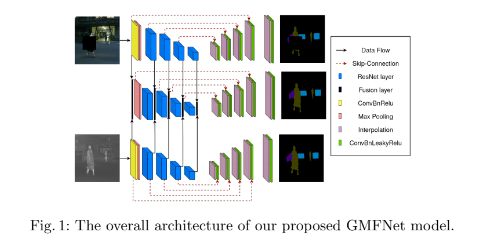
Tout d’abord, cette nouvelle approche se caractérise par une architecture innovante composée de trois U-Net – des réseaux de neurones à convolution – parallèles. Deux U-Nets latéraux traitant chacun une des deux modalités (infrarouge et visible) et un U-Net central chargé de traiter la fusion multimodale.
Si chaque U-Net est composé d’un encodeur et d’un décodeur, les U-Net latéraux utilisent un réseau ResNet pré-entraîné sur ImageNet, duquel sont exclues quelques couches.
Dans nos travaux précédents, nous ne donnions en entrée qu’une image composite, cette nouvelle architecture traite les deux modalités de manière simultanée. De plus, chaque réseau latéral vient pondérer la modalité qu’il traite.
Enfin, et pour aller encore plus loin, le U-Net central apprend à réaliser la meilleure fusion possible en prédisant comment pondérer chaque pixel.
Mécanisme de porte
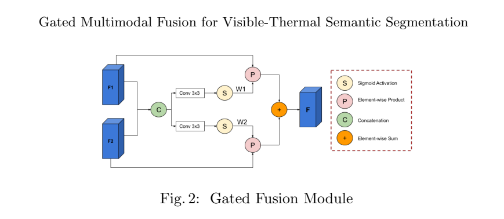
Hormis cette architecture, nous avons également mis en place un mécanisme de porte permettant d’opérer une combinaison dynamique.
Un mécanisme de porte (combinaison dynamique) dans l’encodeur multimodal est utilisé pour pondérer activement chaque modalité au niveau du pixel.
N’étant pas fixe, la combinaison dépend ainsi de l’entrée et de l’information présente dans l’image dans une zone donnée. Et cela, pour chaque modalité.
De plus, le réseau central multimodal apprend à prédire quand une zone de l’image est inexploitable, dans l’une ou l’autre des deux modalités.
Et c’est là que cela devient très intéressant. Avec cette méthode, la fusion multimodale se fera en tenant compte des zones observables et viendra “exclure” les zones non exploitables. Le réseau central privilégiera donc la modalité où il n’y a pas d’anomalies ou de gênes visuelles (éblouissement, occlusion, surface chaude, salissure sur l’objectif, etc.).
Apprentissage multitâche
Dans notre démarche, nous avons également eu recours à de l’apprentissage multitâche.
A priori, nous aurions pu nous contenter d’uniquement entraîner le réseau multimodal – puisque ce dernier est le seul à être utilisé en inférence. Mais nous avons fait le choix d’entraîner les encodeurs unimodaux – les réseaux latéraux – en même temps que le multimodal. Et ce choix s’est avéré judicieux puisque lors des tests, les performances étaient bien meilleures.
Le but de cette méthode est de forcer chaque encodeur unimodal, à bien extraire toute l’information utile dans la modalité qu’il a à traiter.
Par exemple, si les images infrarouges sont peu exploitables, nous ne laisserons pas l’encodeur d’images infrarouges de côté. De force, nous le poussons à extraire un maximum d’informations sur l’image.
Mais pourquoi faire cela ? Pour anticiper une problématique classique en IA : un biais. Le but est d’éviter que, très tôt dans l’apprentissage, le réseau multimodal vienne favoriser une modalité plutôt que l’autre tout en assurant un entraînement de qualité pour les deux encodeurs.
Le vrai plus : l’équilibre performances et budget de calcul
- Notre réseau atteint et dépasse des niveaux de performance à l’état de l’art.
- Or, notre réseau est beaucoup plus petit que les réseaux à l’état de l’art.
- Efficience : nous obtenons donc des performances égales tout en utilisant moins de ressources.
- Il s’agit d’une grande avancée pour l’optimisation de cette tâche de fusion qui ouvre de belles perspectives.
- Cette approche minimise l’impact environnemental et s’inscrit parfaitement dans une démarche d’éco-conception.
- L’entraînement multitâche permet de rendre un modèle plus robuste et généralisable.
- Enfin, notre réseau réussi à allier excellence de performance et temps réel. Une condition sine qua none au déploiement de certaines technologies comme le véhicule autonome.
Cela permet à notre modèle d’être plus robuste face à une détérioration potentielle des capteurs et des images qu’ils peuvent produire sur le terrain.
Augmentation de données
Toujours dans cette optique de robustification, nous avons mené des travaux portant sur de l’augmentation de données.
Pour cela, nous avons simulé des détériorations sur les deux modalités. Ces détériorations prennent la forme d’éblouissements ou d’occlusions (surfaces réfléchissantes, points chauds, occlusions, etc.).
Nous avons fait cela pour une raison très simple : ces détériorations simulent les conséquences de problèmes, défauts ou dommages sur les capteurs mais aussi des conditions d’observation difficiles que nous pourrions retrouver sur le terrain.
En masquant certaines zones de l’image, nous perdons de l’information. Cette perte d’information nous permet d’améliorer la qualité de fusion.
Si le modèle ne pondère pas correctement les deux modalités pour une zone donnée de l’image, la fusion ne transmettra pas la totalité de l’information et une partie de l’image fusionnée ne sera pas exploitable (tâche noire par exemple).
En conséquence, les résultats de segmentations ne seront pas bons puisqu’une partie de l’image ne contiendra aucune information.
Déroulé d’expérimentation
Jeu de données
Pour expérimenter notre approche et évaluer nos résultats, nous avons utilisé le jeu de données MFNet.
Ce jeu de données contient des images visibles et thermiques, idéales pour entraîner un modèle de segmentation sémantique (identifier et différencier un piéton, une voiture, un panneau de signalisation, un trottoir…).
Pour être plus précis, le jeu de données est composé de 1569 paires d’images visibles/thermiques représentant des scènes urbaines d’une résolution de 480×640.
Ensuite, ces paires d’images sont réparties en deux groupes, jour et nuit, en fonction des conditions dans lesquelles elles ont été captées.
Entraînement (la partie un peu technique)
Pour l’entraînement, les encodeurs ResNet sont initialisés en reprenant des poids pré-entraînés sur ImageNet tandis que les autres couches sont initialisées en utilisant le schéma Xavier.
Nous avons combiné les fonctions de perte d’entropie-croisée et d’entropie-croisée pondérée avec des ratios respectifs de 0,8 et 0,2.
Par ailleurs, les poids de classes étaient inversement proportionnels à leur fréquence d’apparition dans le jeu d’entraînement. Moins une classe apparaît, plus son poids est important.
Nous avons ensuite entraîné le modèle avec un optimiseur de descente de gradient stochastique.
Résultats et conclusions
A la suite de cet entraînement, viennent les résultats et leur évaluation.
A titre informatif, les résultats présentés sont issus d’une inférence tournant sur une NVIDIA GTX 1070 GPU.
Concrètement, ils sont excellents et les performances sont au rendez-vous. Nos expériences montrent que l’approche proposée est plus performante que l’état de l’art actuel sur l’ensemble de données MFNet pour une vitesse d’inférence comparable.
En termes absolus, nous avons réussi à dépasser les performances à l’état de l’art. Notre réseau a de meilleures performances que le meilleur réseau concurrent en allant deux fois plus vite en termes de FPS (frames per second, images par secondes en français). Or, plus de FPS induit plus de précision.
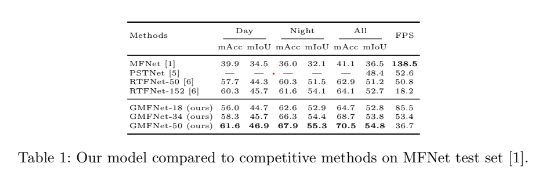
Mais le plus intéressant se situe au niveau du budget de calcul. Les performances se maintiennent même pour un petit réseau. Avec notre réseau de 18 couches, nous atteignons 85fps tout en conservant d’excellentes performances. Des performances proches de celles obtenues par le réseau concurrent de 50 couches.
Qu’est ce que cela implique ? Notre réseau est plus efficace : il tourne plus vite tout en conservant le même niveau de performance. Dans le cadre du véhicule autonome, cela se concrétise par un meilleur temps de réaction, donc des décisions prises plus rapidement et donc des accidents évités.
Outre l’aspect sécuritaire, le fait de miser sur un réseau peu gourmand en ressources permet de faire tourner d’autres réseaux de neurones traitant d’autres tâches en parallèle, sans avoir à augmenter les capacités de calcul.
Review
Strengths/value-added to the community
This paper proposes a three-stream network for semantic segmentation from color (RGB) and thermal (infrared) camera pairs.
The architecture is interesting, well-motivated, and efficient. Each modality uses a standard U-Net architecture. The third stream, also a U-Net, is a fusion encoder-decoder, which learns a gated fusion of the modality-specific encoder features. The whole architecture is trained using a combination of the per stream losses. At test time, the three encoders and the fusion decoder are used for inference.
Thermal imagery has many benefits for real-world robustness, but is still under-explored in the computer vision and AD communities. This paper is a great contribution on that front with modern deep learning techniques, combining good architecture design, multi-task learning, and task-specific data augmentation.
The experimental results show convincing improvements over competing methods.
Weakness/feedback for improvement
The figures are a bit small.
Ablative analysis / baselines: it could be interesting to see how each modality performs trained by itself and trained via multi-task learning. Only fusion methods are compared so far.
Score (according to the quality and suitability for the workshop)
Strong Accept