Les RAG, une révolution dans l’intelligence artificielle
Les RAG, une révolution dans l’intelligence artificielle
L’intelligence artificielle connaît une évolution rapide, et l’une des avancées les plus prometteuses sont les LLMs, les grands modèles de langage, qui représentent une véritable révolution et excellent dans diverses applications, telles que la synthèse d’information, la réponse à des questions de culture générale ou encore la traduction automatique. Cependant, malgré leurs capacités impressionnantes, ils présentent des limitations significatives. Leurs connaissances sont figées dans le temps, basées uniquement sur les données d’entraînement initiales trouvés sur internet à une date donnée (wikipédia, livres, forum, bases de données publiques, etc.), ce qui entraîne une textualisation accrue et une incapacité à intégrer des événements récents ou des informations très spécifiques, comme les données d’une entreprise.
C’est dans ce contexte que le RAG apporte une solution innovante. Contrairement aux approches traditionnelles, le RAG ne se contente pas de générer des réponses basées uniquement sur les données d’entraînement initiales. En effet, le RAG utilise une base de données externe accessible au système, permettant de récupérer et d’intégrer des informations pertinentes et récentes dans les réponses des LLM. Cette technique consiste à stocker les nouvelles données dans une base accessible, que le système RAG peut consulter pour enrichir le contexte des réponses générées par les modèles.
Bien que le RAG n’aborde pas directement la question de la confidentialité des données, ce problème peut être atténué par l’utilisation de modèles open source internes plutôt que des modèles propriétaires externes. En déployant des technologies open source sur le système d’information interne à l’entreprise, plutôt que d’utiliser des solutions externes comme ChatGPT, il est possible de respecter les exigences de confidentialité des données des entreprises.
Enfin, plutôt que de réentraîner continuellement les modèles sur de nouvelles données, ce qui peut s’avérer impossible en pratique car trop cher en terme de puissance de calcul, le RAG propose une alternative efficace en intégrant dynamiquement des informations externes pour améliorer la qualité et la pertinence des réponses des LLMs.
Dans cet article, nous explorerons en profondeur le fonctionnement du RAG, ses avantages par rapport aux solutions du marché comme ChatGPT, et comment il peut transformer l’utilisation des LLMs dans divers domaines.
Qu’est-ce que le RAG ?
Le RAG est l’acronyme pour Retrieval Augmented Generation. C’est une méthode hybride intégrant plusieurs processus clés pour améliorer la qualité des réponses générées par les grands modèles de langage (LLM). Il se distingue par sa capacité à utiliser des informations externes pour enrichir les réponses, offrant ainsi une précision et une contextualisation accrues. Contrairement aux approches traditionnelles, le RAG ne se contente pas de générer des réponses basées uniquement sur un modèle pré-entraîné, mais il intègre des données actualisées et pertinentes pour chaque requête. Cela se fait en plusieurs étapes principales, la préparation de la base de données, la récupération d’informations, l’augmentation des données et la génération de texte.
Comment fonctionne le RAG ?
Le processus RAG se déroule en quatre étapes distinctes, la préparation de la base de données, la récupération d’informations, l’augmentation des données et la génération de texte, chacune jouant un rôle crucial dans la production de réponses de haute qualité.
Tout commence par la préparation de la base de données, il est nécessaire de nettoyer et préparer les données, souvent extraites de documents non structurés tels que des fichiers PDF ou Word. Des outils peuvent aider à transformer ces documents sous format texte pour pouvoir être compris par les LLMs. La redondance d’information doit être limitée pour optimiser les résultats de recherche. L’information est découpée en morceaux (chunks), chaque morceau ayant son embedding calculé (vecteur de nombres) et enregistré avec des métadonnées, pour améliorer la recherche. La segmentation doit être adaptée à la nature du contenu et au cas d’usage.
Une fois la base de données prête, le processus continue avec la formulation de la requête, où l’utilisateur pose une question ou fournit une requête textuelle. Le système analyse ensuite cette requête et utilise des techniques de recherche d’information pour identifier les documents ou passages les plus pertinents pour y répondre, que ce soit dans des bases de données structurées ou des corpus de textes non structurés.
Une fois les données pertinentes récupérées, elles sont enrichies et contextualisées. Ce processus d’augmentation peut inclure l’ajout de contexte, la fusion de données de différentes sources, ou le nettoyage des données pour améliorer leur qualité. Cette étape est nécessaire pour s’assurer que les informations utilisées sont non seulement pertinentes, mais aussi complètes et précises. Enfin, le modèle de génération de langage utilise ces informations augmentées pour produire une réponse textuelle cohérente et pertinente. La réponse générée est alors présentée à l’utilisateur, qui peut interagir davantage avec le système si nécessaire.
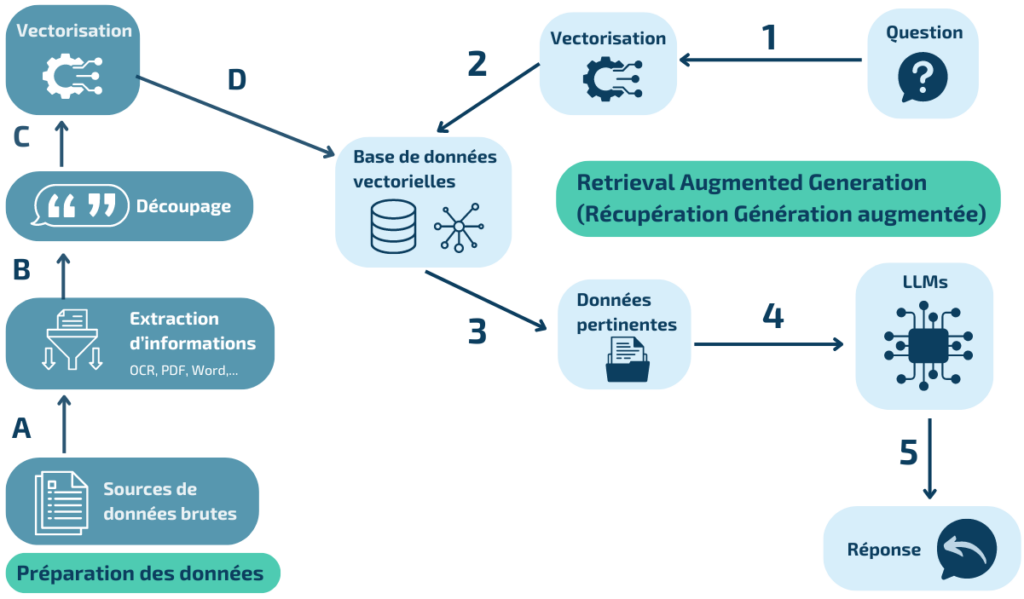
Fonctionnement du RAG
Compréhension de la « context window »
La « context window » représente la limite d’information que le modèle peut traiter en entrée et en sortie. Il est essentiel de prendre en compte cette limite lors de l’utilisation des modèles de langage. Plus l’information en entrée est importante, plus la réponse sera lente et coûteuse. Le RAG, en utilisant des embeddings pour vectoriser l’information et permettre la recherche par similarité, fait face à cette limitation en sélectionnant parmi les contenus retrouvés les plus pertinents.
Impossible donc de fournir tous les documents de votre entreprise à un LLM pour lui demander une réponse à une question précise. Il faut ajouter une étape qui consiste à extraire seulement la partie utile de l’information.
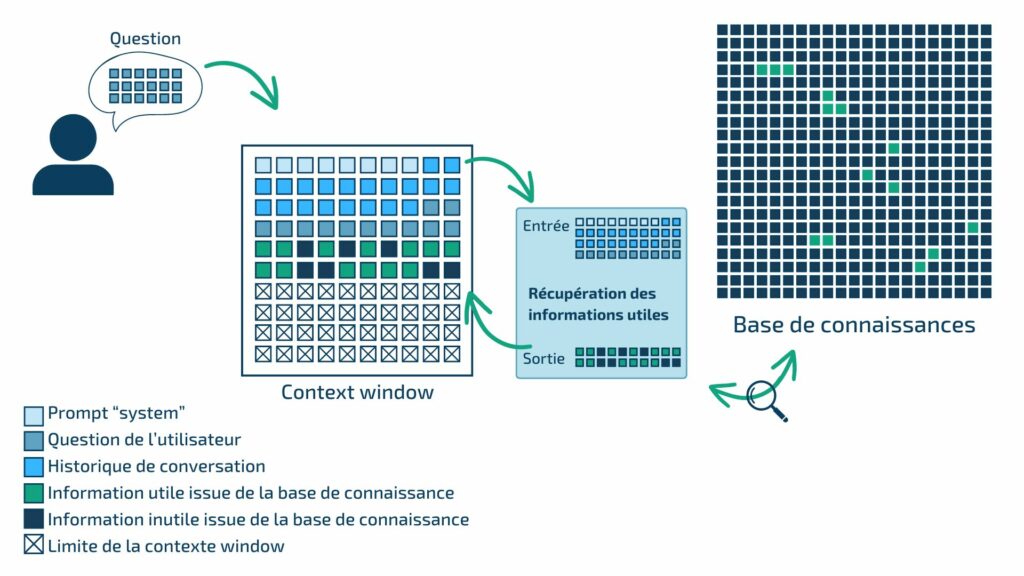
Récupération de l’information utile
Comment le RAG améliore les performances d’un LLM ?
Le RAG offre plusieurs avantages significatifs par rapport à des technologies comme les LLMs. L’un des principaux avantages est la réduction des erreurs. En utilisant des données externes et actualisées, le RAG diminue les risques de générer des informations incorrectes ou inventées, appelées hallucinations. De plus, le RAG permet une personnalisation poussée en utilisant des documents spécifiques de l’entreprise, ce qui permet de fournir des réponses précises et adaptées aux besoins particuliers de chaque utilisateur tout en citant ses sources, permettant ainsi à l’utilisateur de vérifier la véracité de l’information générée.
Le RAG permet d’augmenter la performance d’un modèle open source tout en maintenant la confidentialité des données. En utilisant le RAG, on peut améliorer les capacités du modèle open source et ainsi garantir que les données sensibles restent dans un environnement informatique contrôlé et sécurisé par l’entreprise. De plus, un RAG peut être utilisé avec n’importe quel LLM : plus le modèle est performant, meilleures seront les réponses fournies. La mise à jour des connaissances se fait simplement en remplaçant le corpus documentaire indexé par le RAG, sans nécessiter un ré-entraînement complet, minimisant ainsi les risques de fuite de données privées.
Principe des embeddings et techniques de recherche
Un embedding est une représentation vectorielle d’un mot ou d’un groupe de mots. Dans le contexte du RAG, les embeddings correspondent aux données contenues dans les documents (chunks).
Les embeddings permettent de représenter un texte sous forme de vecteur dans un espace à haute dimensions. Des textes proches sémantiquement sont proches dans cet espace. Lorsqu’une question est posée, l’embedding de la question est comparé aux embeddings de la base de connaissances pour retenir les plus proches. Cela permet d’utiliser la connaissance externe sans intégrer toute la base dans la context window.
Néanmoins, le RAG n’est pas infaillible. Si les informations trouvées ne sont pas de bonne qualité, l’IA n’a pas conscience de la globalité de la base de connaissances et peut produire des réponses inexactes ou partielles. Les paramètres influençant les résultats incluent le choix de l’algorithme d’embedding, la qualité et la structuration des données, ainsi que le type de question posée.
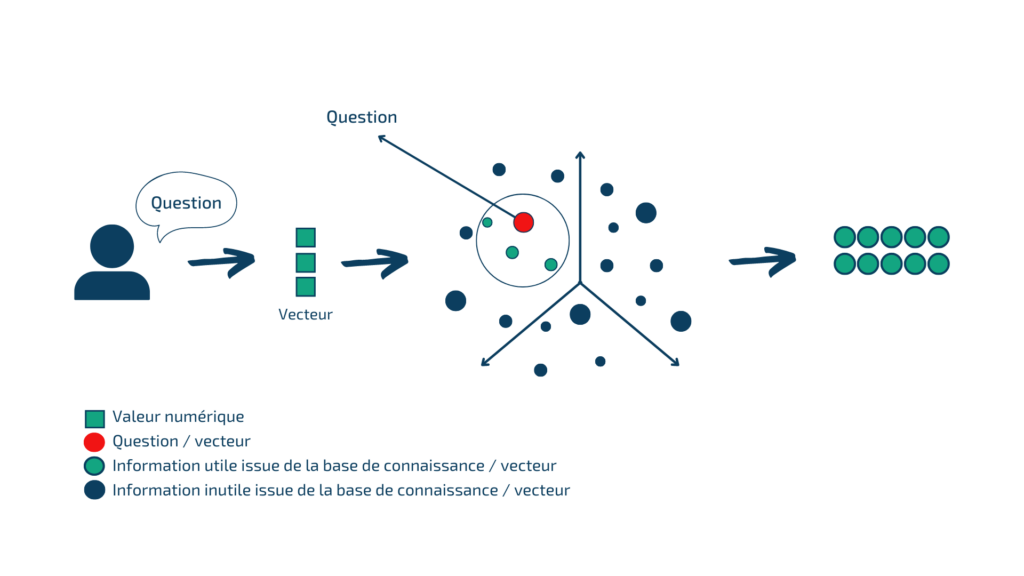
Pipeline de la recherche vectorielle pour la récupération d’informations utiles afin de répondre à la question utilisateur
Comparaison entre le RAG et le fine-tuning
Le fine-tuning consiste à prendre un LLM pré-entraîné et à le former davantage sur un plus petit jeu de données, souvent avec des données non utilisées précédemment pour l’entraînement du LLM, afin d’améliorer sa performance pour une tâche particulière.
Cependant, cette approche présente des inconvénients : il faut réentraîner le modèle chaque fois que l’on souhaite ajouter un document ou pour chaque nouvelle tâche, ce qui pose les mêmes problèmes qu’auparavant. De plus, ce processus nécessite une puissance de calcul considérable pour chaque nouvel entraînement.
En revanche, le RAG permet d’augmenter la qualité de la réponse du LLM avec des données inconnues lors de l’entraînement, comme des données récentes, des données personnelles de l’utilisateur, des données de l’entreprise ou encore des informations contextuelles utiles.
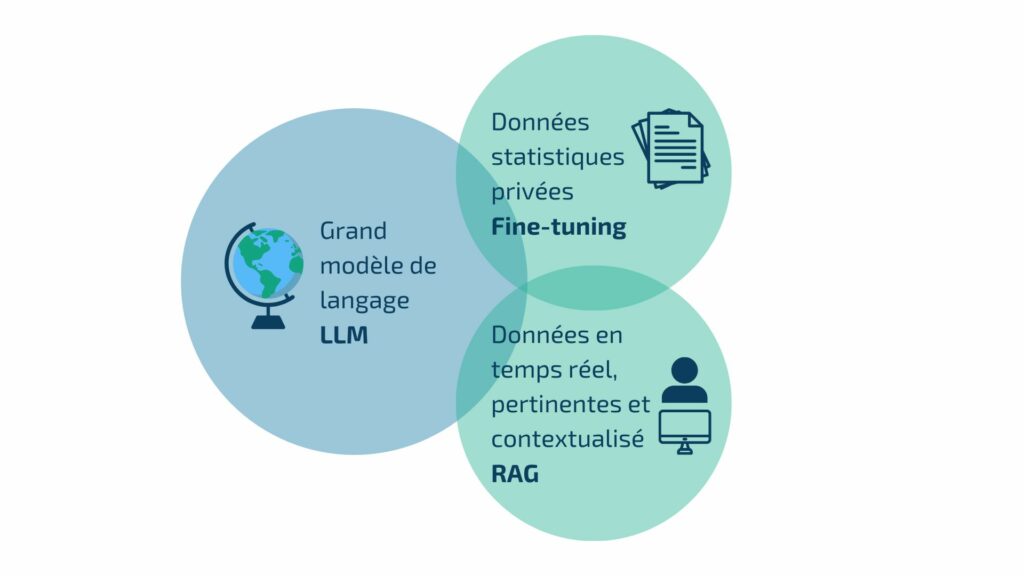
Les LLM peuvent être étendus avec RAG et Fine-Tuning
Applications du RAG
Les applications du RAG sont vastes et variées, touchant de nombreux domaines.
Dans les secteurs de la relation client, un RAG peut fournir des réponses précises et contextuellement riches aux questions des utilisateurs (FAQ intelligente), améliorant ainsi l’expérience client et l’efficacité des services d’assistance.
Dans le secteur de la R&D, le RAG peut aider les équipes dans leur veille scientifique et technique, en leur permettant de poser des questions à une grande quantité de publications, articles ou brevets. Cela facilite l’innovation et le développement de nouveaux produits en offrant une vue complète et à jour d’un domaine de recherche.
Dans le domaine de la maintenance, le RAG permet de poser des questions en langage naturel à des documents techniques parfois longs et complexes, facilitant ainsi la recherche de réponse à des questions techniques précises.
Plus généralement dans les entreprises, le RAG améliore la gestion de la connaissance en rendant les informations internes plus facilement accessibles. Cela permet aux employés de trouver rapidement les informations présents dans des documents (processus, documentation technique, communication interne, etc.) en posant des questions en langage naturel, améliorant ainsi l’efficacité opérationnelle.
Les avantages et les défis du RAG
Les systèmes RAG offrent des avantages significatifs. En combinant la récupération et l’augmentation de données avec la génération de texte, les systèmes RAG peuvent fournir des réponses plus précises et pertinentes. L’augmentation des données permet de fournir des réponses mieux contextualisées, cruciales pour des domaines nécessitant une compréhension approfondie. De plus, les systèmes RAG peuvent traiter et synthétiser rapidement de grandes quantités d’informations, ce qui est bénéfique dans des environnements nécessitant une prise de décision rapide.
Cependant, le RAG présente aussi des défis. La mise en œuvre de systèmes RAG nécessite une infrastructure complexe, des modèles avancés et la transformation des documents en base de données vectorielle. La précision des systèmes RAG dépend de la qualité des données récupérées et augmentées. Des données de mauvaise qualité peuvent entraîner des réponses incorrectes.
Enfin, les modèles de langage et les techniques de récupération d’information doivent être continuellement mis à jour pour maintenir leur efficacité face à l’évolution rapide de ces nouvelles technologies.
Conclusion
Le RAG représente une avancée majeure dans le domaine de l’intelligence artificielle. En combinant la préparation de la base de données, la récupération d’information, l’augmentation des données et la génération de texte, il offre des systèmes plus puissants, précis et adaptés aux besoins spécifiques des entreprises. Bien que les défis demeurent, les applications potentielles des RAG sont vastes et prometteuses, ouvrant la voie à de nouvelles possibilités dans de nombreux secteurs. Le RAG pourrait bien transformer notre manière d’interagir avec nos systèmes d’information, offrant des interactions homme-machine plus rapides, ergonomiques et personnalisées.
Sources
Une partie de nos illustrations sont inspirées de :
Premiers pas avec le Retrieval Augmented Generation (RAG) | Digi-Stud.io : https://digi-stud.io/blog/2024-ai-rag/
Techniques, Challenges, and Future of Augmented Language Models | Gradient Flow : https://gradientflow.com/techniques-challenges-and-future-of-augmented-language-models/
Retrieval Augmented Generation (RAG) for LLMs | Hopsworks : https://www.hopsworks.ai/dictionary/retrieval-augmented-generation-llm