
Neovulga – Veille Vulgarisée – DeepSIM
Neovulga – Veille Vulgarisée – DeepSIM
A Neovision, nous menons une veille scientifique constante pour rester à l’état de l’art. Chaque mois, les dernières avancées sont présentées à l’ensemble de l’équipe, que ce soit de nouveaux jeux de données, un nouveau papier de recherche… Nous passons toutes les actualités – ou presque – au crible. Dans notre ambition visant à mettre l’IA à la portée de tous, nous vous proposons, chaque mois, l’analyse vulgarisée d’un sujet technique présenté par notre cellule R&D.
Ici, nous traiterons de l’article scientifique Image Shape Manipulation from a Single Augmented Trained Sample, par Yael Vinker, Eliahu Horwitz, Nir Zabari, Yedid Hoshen.
Contexte
Il existe depuis longtemps des méthodes permettant de manipuler les images, notamment dans le cadre de la retouche photo. DeepSIM fait partie de ces méthodes, tout en ayant la particularité de réaliser un grand nombre de manipulations. Enlever des objets, en rajouter, les déformer… À savoir que les manipulations complexes offertes par DeepSIM étaient jusqu’alors non adressées par d’autres méthodes.


Parmi les autres travaux qui se sont penchés sur de la génération d’image, on peut en citer deux principaux : SinGAN et TuiGAN. SinGAN est un modèle génératif ne permettant pas la manipulation d’images. En revanche, il permet de simuler des variantes de l’image en entrée. TuiGAN de son côté, a apporté la notion de transformation d’une image source vers une image cible. Toutefois, les images ne sont pas appareillées entre elles. Il s’agit plutôt d’un transfert de style.
L’avancée présentée
DeepSIM permet donc des manipulations d’images complexes. Pour ce faire, il se sert uniquement d’une paire d’images. Une dite “complexe”, ainsi qu’une représentation simplifiée de cette image. L’image complexe n’appartenant pas forcément au monde réel. Par la suite, c’est par la manipulation de la représentation simplifiée que les modifications seront reproduites sur l’image complexe. Ce qui rend la manipulation de l’image moins fastidieuse.
Comment cela fonctionne-t-il ? Concrètement, DeepSIM utilise beaucoup d’augmentation de données. Afin d’utiliser cette seule paire d’images, on vient déformer les images.
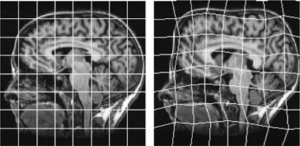
DeepSIM utilise en particulier ce qu’on appelle une déformation non rigide, à l’image de l’exemple dans l’image ci-dessus. La transformation précise utilisée dans ce papier est nommée Thin Plate Spline. Cette déformation non rigide est un ajout important de ce papier puisqu’elle permet de créer suffisamment de diversité à partir d’une seule paire d’images pour pouvoir apprendre un modèle qui généralise à d’autres déformations. À côté de cette déformation, on applique alors d’autres transformations diverses à l’image. Rotation, déformation affine… Les choix sont multiples.

L’édito d’Etienne
Parfois certains papiers vous sautent aux yeux tant les résultats sont saisissants et nouveaux ! C’est le cas avec DeepSIM, une méthode qui permet de créer une animation à partir d’une photo. De quoi attiser ma curiosité et chercher à comprendre comment les auteurs ont accompli cette prouesse. On vous explique ci-dessous le principe de fonctionnement plus en détail.
La nouveauté de ce papier est bien dans cette façon d’entraîner à partir d’une seule paire d’image et non du côté du modèle en lui-même. En effet, les auteurs utilisent un modèle existant appelé Pix2Pix et conçu pour la traduction d’image. Pix2Pix fait partie de la grande famille des GANs. C’est même plus précisément un GAN conditionnel (cGAN). La différence entre les deux étant qu’un GAN conditionnel, à l’inverse d’un GAN “traditionnel”, offre la possibilité de contrôler la génération de données en fonction de conditions. Il permet ainsi l’intégration d’informations additionnelles, telles que des étiquettes, afin de spécifier la génération souhaitée en sortie. Dans le cas de Pix2Pix, la condition est une image, passée en entrée du réseau, que l’on souhaite transformer en une autre image, par exemple en ayant modifié le style. D’où le nom Pix2Pix pour image (d’entrée) à image (de sortie).
Plusieurs limites semblent toutefois émerger de DeepSIM. À l’image complexe sont ajoutés des traits, des ajouts sûrement manuels qui viennent augmenter le niveau de détail de l’image. Il serait intéressant de voir les performances sans ces traits, pour ainsi déduire quel niveau d’information ces derniers viennent apporter. Enfin, DeepSIM produit des résultats avec des artéfacts. Son utilisation reste donc limitée, pour l’instant, à accélérer des phases ou la perfection du rendu n’est pas impérative. Par exemple dans les phases intermédiaires de la production d’un film d’animation.
Pourquoi c’est cool ?
DeepSIM trouve tout son intérêt dans les applications créatives. Il permettrait ainsi d’itérer plus rapidement sur des tâches créatives. À l’image de l’exemple ci-dessous, il pourrait être possible de créer aisément différents patrons de robes ayant le même motif.

Autre domaine d’application, celui de l’animation. DeepSIM serait là aussi un facilitateur, en accélérant le travail des créatifs. Il pourrait permettre de prévisualiser les animations, en dessinant les images avec moins de détails. Ces modifications seraient par la suite automatiquement reproduites d’une image sur l’autre.