
De la donnée brute à la donnée exploitable par l’IA
Avant de parler IA, il faut forcément parler data.
Avant de pouvoir être exploitées, vos données ont un petit bout de chemin à parcourir ! Car, non, il ne suffit pas de simplement les rassembler dans un jeu de données. Quelques étapes préalables sont indispensables. Après cela, vous serez parés à l’action !
I – Qu’est-ce qu’une donnée ?
Un peu de théorie, mais pas trop, pour commencer. Juste de quoi avoir une base commune sur ce que l’on appelle une donnée, et comment la différencier d’une information, ou encore d’une connaissance.
A – Définition de la donnée
À l’ère d’internet et du Big Data, les données sont omniprésentes dans notre environnement. D’ailleurs, vous en générez au quotidien, peut-être même sans vous en rendre compte. Mais sauriez-vous définir précisément ce qu’est une donnée ?
Il se trouve qu’il existe une grande variété de données. En pratique, elles se manifestent comme étant des observations, des mesures, des faits ou encore des descriptions. Mais cela ne s’arrête pas là ! Les formats que peuvent prendre ces données sont nombreux. On peut ainsi se trouver face à des textes, des images, des vidéos, des statistiques ou bien des séries temporelles.
Outre cette diversité touchant à la nature même de la donnée, nous retrouvons cette même diversité au niveau des sources de données. Vous pouvez capter ces données par vos propres moyens, et ainsi créer une base de données interne. Mais, il vous est également possible de vous appuyer sur des jeux de données externes, que vous pouvez chercher un peu partout (projets connexes, concurrents, open data…). Et, si vous avez pour ambition de vous lancer dans un projet IA, un jeu de données peut venir compléter l’autre. Ainsi, des données externes viendront s’ajouter aux données déjà collectées en interne, soit pour les augmenter, soit pour amener de nouvelles variables affinant les prédictions de votre modèle.

Les données tout juste recueillies sont dites brutes et non structurées, à moins d’avoir bien anticipé en créant un pipe data en amont. Dans l’objectif d’être analysées, elles nécessiteront un formatage et un nettoyage afin d’assurer toute leur pertinence. Pour ce qui est du nettoyage, il consistera à supprimer les données incomplètes, dégradées ou tout simplement fausses. Niveau structuration, les données seront dites structurées dès lors que l’on sait ce que contient chaque élément d’une donnée et où le trouver.
À ce titre, la base de données va alors être enrichie de métadonnées. Une métadonnée, c’est un ensemble de détails spécifiques sur les données qui permettent de mieux les comprendre, les qualifier et de les transformer en information. L’étape d’annotation, sur laquelle on reviendra plus bas dans cet article, est une des manières de générer des métadonnées.
B – Donnée, information, connaissance… Quelles différences ?
A première vue, difficile de différencier ces trois notions, et pourtant, c’est tout à fait essentiel !
Pour faire simple, la donnée est un élément brut que l’on n’a pas encore interprété. Elle est donc uniquement composée de faits, de chiffres bruts et de propriétés intrinsèques. Cette donnée va alors servir à générer des informations. En effet, une information n’est rien de plus qu’une donnée qui a été interprétée. Quant à la connaissance, elle s’inscrit dans la continuité de l’information, tout en ayant un sens bien plus large. C’est une information qui a été assimilée et utilisée dans le but d’aboutir à une action.
C – Focus sur les données visuelles
Parce que la Computer Vision est notre cœur de métier, intéressons-nous maintenant à un type de données bien particulier, les données visuelles.
Tout d’abord, il nous paraît important de rappeler que ces données visuelles peuvent prendre plusieurs formats. Ainsi, une image pourra aussi bien être au format JPEG, que PNG ou encore PDF. Le même principe s’applique aux vidéos. Bien entendu, outre le format, les dimensions sont aussi variables et sont en général exprimées en pixels. Il est de plus en plus commun de trouver des formats standards, comme COCO, largement utilisés actuellement.
Particularité des données visuelles, et pas des moindres : la modalité. Lorsque l’on pense à une donnée visuelle, on fait par habitude le lien à une photo du domaine visible, et donc capturée par une caméra du quotidien. Or, de multiples capteurs existent. Ceux-ci peuvent être thermiques, infrarouges, à rayons X ou encore multispectraux et ils généreront donc des images spécifiques.

Ces 3 éléments : format, dimension et modalité, sont importants à garder en tête. En effet, tous ne seront pas exploitables par tous les algorithmes. Certains requièrent des données spécifiques en entrée. Plus concrètement, cela peut être des images RGB, de dimensions carrées 500×500 au format PNG.
II – Comment rendre ses données exploitables ?
Maintenant, parlons pratique. Rendre vos données exploitables nécessite dans un premier temps un grand nettoyage. Après cela, viendra une étape cruciale : celle de l’annotation.
A – Faut-il tendre à l’exhaustivité, à la représentativité ?
On entend régulièrement dire que le Machine Learning nécessite de grandes quantités de données. Si c’est bien vrai pour le Deep Learning, une branche du Machine Learning, en réalité, le plus important est que votre base de données soit représentative, et si possible, exhaustive. Mais pour le dernier point, on parle ni plus ni moins d’un Graal.
Des données représentatives permettront de refléter au mieux la réalité terrain, et donc les cas de figure que l’IA aura à analyser une fois utilisée. Cela assure que les données utilisées durant l’apprentissage seront proches de celles que l’IA aura à traiter une fois mises en production. Cette représentativité des données est un véritable facteur clé de succès dans le développement d’une IA. Elle cause des pertes de performances importantes si l’on passe à côté.
Quant à l’exhaustivité, elle permet de s’assurer que le jeu de données représente tous les cas de figure que l’IA pourra rencontrer. Réussir à être totalement exhaustif est utopique, mieux vaut alors viser une exhaustivité relative, mais la plus large possible.
B – Nettoyer, structurer et traiter ses données
L’heure de rendre vos données brutes enfin exploitables a sonné, alors on se retrousse les manches !
Dans un premier temps, le nettoyage de vos données va permettre de s’assurer qu’elles sont fiables. Pour cela, on vérifie qu’il n’y pas de données manquantes ou aberrantes. Celles qui sont totalement incohérentes sont alors supprimées ou les éventuelles erreurs corrigées. Cette étape permet de s’assurer que l’on disposera d’informations de qualité optimale avant l’entraînement du modèle.
Nettoyer ses données, c’est bien, mais pas suffisant et cette tâche devient même laborieuse quand les données ne sont pas structurées.
Quand nous parlons de données structurées, nous pouvons voir cela comme une standardisation, un format spécifique pour organiser ses données. Pour des données visuelles, nous pourrions parler de format spécifique ou même de classes dans lesquelles il faut les ranger. Pour des données tabulaires, il s’agirait d’avoir le même nombre de dimensions (nombre de colonnes) pour chaque donnée (une ligne dans le tableau). Ainsi la colonne A donnerait toujours le même type d’information pour chaque donnée. Cette structuration permet de mettre en évidence certaines données incomplètes ou particulièrement fausses.
Si la structuration et le nettoyage amènent une solution assez drastique en supprimant les mauvaises données, certains traitements permettent de les “réhabiliter”.
En effet, la qualité des prises de vues dépend fortement des conditions du monde réel. Par exemple, un changement d’éclairage peut modifier l’apparence d’un objet en un clin d’œil. Ou, si l’on est face à un objet en mouvement, un mauvais angle de vue peut tout bonnement empêcher de le reconnaître. C’est dans ces situations que le traitement d’images prend tout son sens.
Le traitement que l’on vient appliquer à l’image peut être minime, comme un petit recadrage ou une rotation. Mais il est également possible de venir modifier l’image, en touchant à ses propriétés, afin de mettre en lumière certains éléments, ou par exemple de supprimer un bruit causé par un éclairage faible. Ces traitements correctifs peuvent aussi être faits dans l’autre sens, pour amener de la variabilité dans votre jeu de données. On appelle cela la Data Augmentation ou Augmentation de données. Non, nous n’avons même pas eu besoin d’utiliser DeepL pour cette traduction.
C – Annoter ses données
L’étape finale, on en parlait justement plus tôt, c’est l’annotation. Le passage incontournable qui permet de décrire et de qualifier ses données.
L’idée de base est la suivante. Si l’on souhaite reconnaître des chats et des chiens, il faudra avant tout constituer une base de données d’images représentant des chats et des chiens. Pour chaque photo, on vient ensuite indiquer si elle représente un chien et/ou un chat. Pour ce faire, on ajoute une méta données, une étiquette renseignant la classe de l’image. Ici, le jeu de données à exploiter sera donc composé de photos avec des étiquettes “chien” ou “chat”. L’annotation permet alors de diviser le jeu de données en deux classes, soit celles que l’on souhaite identifier.
En Computer Vision, l’annotation d’images est notamment utilisée pour des tâches de classification, de détection ou encore de segmentation. Les méthodes d’annotation viennent différer en fonction de la tâche visée.
La classification d’image vise à ranger une image dans une classe spécifique. Si l’on reprend notre jeu de données de chats et de chien et ses étiquettes, l’IA viendra exploiter les métadonnées pour ensuite pouvoir apprendre à quoi ressemble un chien pour ensuite pouvoir nous indiquer si l’on est face à l’un ou à l’autre. Pour faire simple, c’est comme lorsque l’on apprend à un enfant ce qu’est une pomme. Nous allons lui montrer une pomme , mais nous allons aussi lui dire que ceci est une pomme.

Et, dans le cadre où l’on aurait un chat ET un chien sur la même image, pas de panique ! Il est possible de s’appuyer sur un classifieur multilabels, capable d’attribuer plusieurs classes à une même image.
Quant à la détection, à première vue, elle semble assez proche de la classification. Or, celle-ci apporte une dimension supplémentaire, en permettant de localiser la position du chien sur votre image. Pour annoter des données dans ce cadre applicatif, nous devons indiquer les coordonnées spatiales de l’animal en dessinant une zone rectangulaire autour. Celle-ci est plus communément appelée boîte englobante, ou “bounding box”. Ces bounding box sont des métadonnées qui seront exploitées par l’algorithme d’apprentissage pour pouvoir modéliser un détecteur de chiens et de chats sur de nouvelles photos.
En pratique, le détecteur se double généralement d’un classifieur. Cela permet de reconnaître l’objet souhaité, en plus de détecter sa position précise.
Dernière tâche que l’on abordera ici : la segmentation sémantique. Une application plus avancée que l’on pourrait plus ou moins voir comme la version améliorée de la détection ! Ici, plus de boîte englobante pour annoter, mais une définition de la forme de l’objet pixel par pixel appelée masque de segmentation. Les images annotées doivent donc comporter des masques apposés sur les objets nous intéressant.
D – Identifier et éviter les biais
Vérifier la représentativité de son jeu de données, le structurer, le nettoyer… Ces traitements visant à rendre un jeu de données exploitable tendent également vers un objectif commun : identifier et éviter les biais présents.
En effet, si votre jeu de données n’est pas représentatif, gare aux biais ! Votre modèle en production, en plus d’intégrer les biais présents, risque même de venir les exacerber. Et le jeu n’en vaut clairement pas la chandelle.
Prenons comme exemple le jeu de données ci-contre. A première vue, on pourrait penser qu’il est équilibré si l’on s’intéresse à la distribution des genres. Or ici, les hommes sont surreprésentés dans les activités extérieures et sportives. De leur côté, les femmes sont surreprésentées dans les activités d’intérieur, et encore plus en cuisine. Lors de l’utilisation de ce jeu de données pour l’entraînement, on va donc venir intégrer ces biais. Cela signifie que le modèle classifiera plus facilement un humain comme étant une femme si celui-ci se situe dans une cuisine.
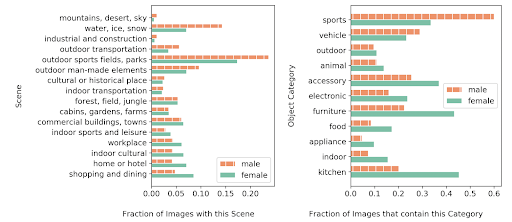
Fort heureusement, identifier les biais est bien plus facile lorsque les données sont structurées. Et pour les éviter, diverses méthodes peuvent être mises en place mais toutes se basent sur une logique d’enquête.
La première consiste en une analyse manuelle et visuelle. Comme pour l’exemple ci-dessus, on peut avoir l’intuition de l’existence d’un biais par observation du jeu de données. Une intuition validée lors d’une analyse plus poussée (comme avec les graphiques ci-dessus). Mais attention, cette méthode n’est valable que lorsque le jeu de données est à échelle humaine. Difficile de prétendre pouvoir analyser des milliers d’images avec vos petits yeux d’humain !
La seconde méthode consiste à s’appuyer sur l’utilisation de technologies pour venir valider les potentielles intuitions de biais. Pour ce faire, traitements mathématiques et outils de data engineering seront vos amis. Notre outil Tadaviz vous assiste notamment dans l’analyse de la bonne distribution de votre jeu de données de manière très visuelle.
Conclusion
Et voilà, vous connaissez désormais la marche à suivre afin de rendre vos données exploitables, et il y a du boulot ! Pourtant, quelques problématiques peuvent persister. En particulier, le bon dimensionnement de votre jeu de données peut être délicat. Le vôtre est trop petit, ou bien trop grand ? Pour résoudre cela, plusieurs solutions sont à votre portée. On vous explique ça ?
Sources :
- https://neovision.fr/intelligence-artificielle-opportunite-entreprise/
- https://neovision.fr/prerequis-intelligence-artificielle/
- https://neovision.fr/ia-cognito-ep06-computer-vision/
Pingback: Data augmentation : des solutions face au manque de données